
 如何实现唯一的分布式 ID
如何实现唯一的分布式 ID
# 1.UUID
UUID.randomUUID().toString()
【优点】
- 本地生成无网络消耗,并具有唯一性。
【缺点】
- 长度较长且无序,也没有实际意义;
- 不适用于实际的业务需求。像用作订单号UUID这样的字符串没有丝毫的意义,看不出和订单相关的有用信息;
- 如果做mysql表主键的话,由于mysql的底层存储结构是B+树,节点在排序等操作时,性能差于整型。
# 2.UUID转Long的方式
UUID.randomUUID().getMostSignificantBits() & Long.MAX_VALUE
查看UUID类的toString()方法,会发现UUID是由高64位和低64位组合而成:
public String toString() {
return (digits(mostSigBits >> 32, 8) + "-" +
digits(mostSigBits >> 16, 4) + "-" +
digits(mostSigBits, 4) + "-" +
digits(leastSigBits >> 48, 4) + "-" +
digits(leastSigBits, 12));
}
2
3
4
5
6
7
UUID的高64位与0111111111111111111111111111111111111111111111111111111111111111做按位运算,可保证生成的id始终为正数。
# 3.数据库自增ID
基于数据库的auto_increment自增ID。
CREATE DATABASE `SEQ_ID`;
CREATE TABLE SEQID.SEQUENCE_ID (
id bigint(20) unsigned NOT NULL auto_increment,
value char(10) NOT NULL default '',
PRIMARY KEY (id),
) ENGINE=MyISAM;
insert into SEQUENCE_ID(value) VALUES ('values');
2
3
4
5
6
7
8
【优点】
- ID自增,数值类型存取性能好;
【缺点】 1.单点要防止宕机风险; 2.集群模式难扩展,比如步长。
# 4.Redis的incr自增
【优点】
- Redis的优点是单线程、免去了线程间切换的开销,存取速度快。
【缺点】
- Redis满足分布式CAP原则中的A(Availability可用性)、P(Partition tolerance分区容错性),不能满足C(Consistency一致性),也就是说Redis无法保证在主节点宕机时自动完成数据一致性的同步操作。那么在极端情况下,主节点挂掉后可能产生重复的id。
- 即使考虑用持久化的方式来规避上面的问题,仍存在以下缺陷: RDB方式:定时备份,可能存在数据丢失。假如连续自增但redis没及时持久化,而此时Redis挂掉了,重启Redis后可能会出现ID重复的情况。 AOF方式:每条写命令都备份,不会出现ID重复的情况,但文件过大,恢复数据慢。
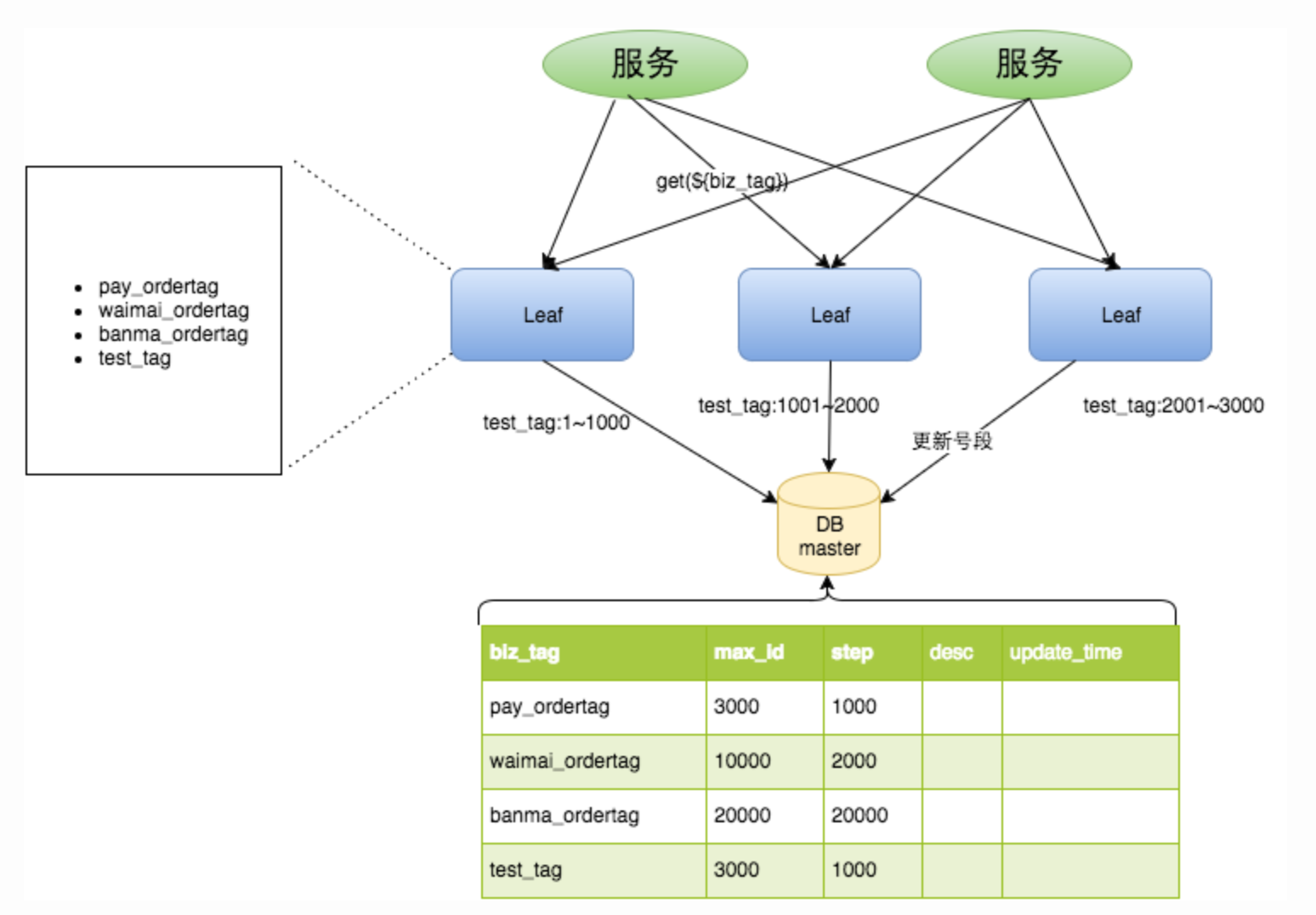
# 5.数据库号段模式
用表记录当前最大id,和自增步长。每次机器通过乐观锁的方式修改当前最大id字段:
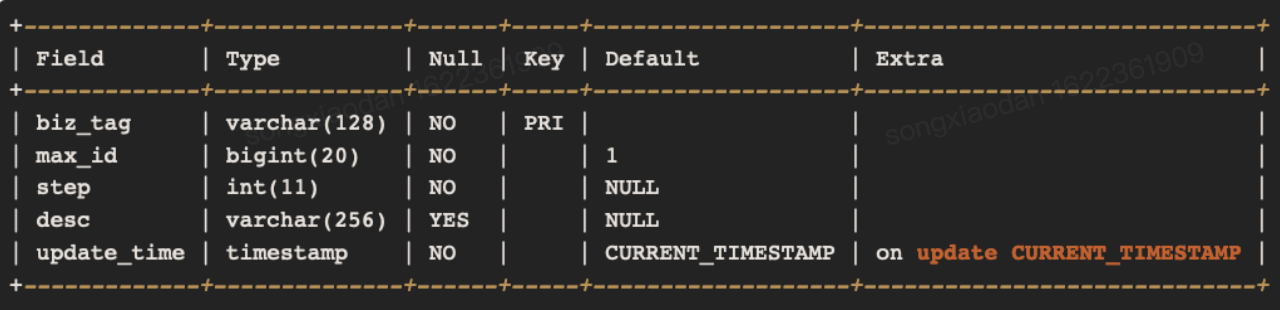
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = #{version} and biz_type = XXX
【优点】
不会频繁的访问数据库,对数据库的压力小很多。
【图示】
# 6.Snowflake
【组成】
 符号位:1bit:符号位,固定是0,表示全部ID都是正整数
时间戳:与指定日期的时间差(毫秒级),41位,够用69年
集群ID、机器ID:10位,最多支持1024台机器
自增序列:12位,每台机器每毫秒内最多产生2^12即4096个序列号
【优点】
符号位:1bit:符号位,固定是0,表示全部ID都是正整数
时间戳:与指定日期的时间差(毫秒级),41位,够用69年
集群ID、机器ID:10位,最多支持1024台机器
自增序列:12位,每台机器每毫秒内最多产生2^12即4096个序列号
【优点】
- 本地生成无网络消耗。
【缺点】
- 依赖系统时间,如果系统时间被回调,或者改变,可能会造成id冲突或者重复,也能出现不是全局递增的情况。
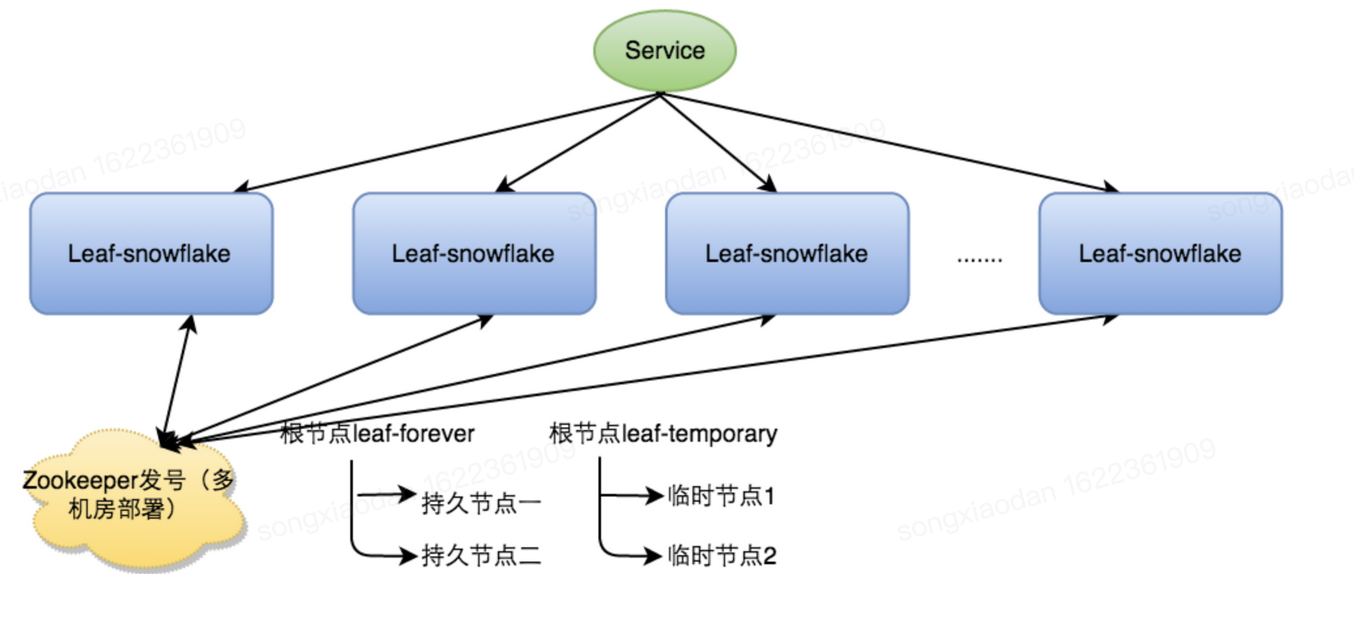
# 6.Leaf-snowflake(美团)
美团对号段模式和雪花算法的实现方式均有改进。
【文档】
https://tech.meituan.com/2017/04/21/mt-leaf.html
【得名】
德国哲学家、数学家莱布尼茨的一句话: >There are no two identical leaves in the world > “世界上没有两片相同的树叶”。
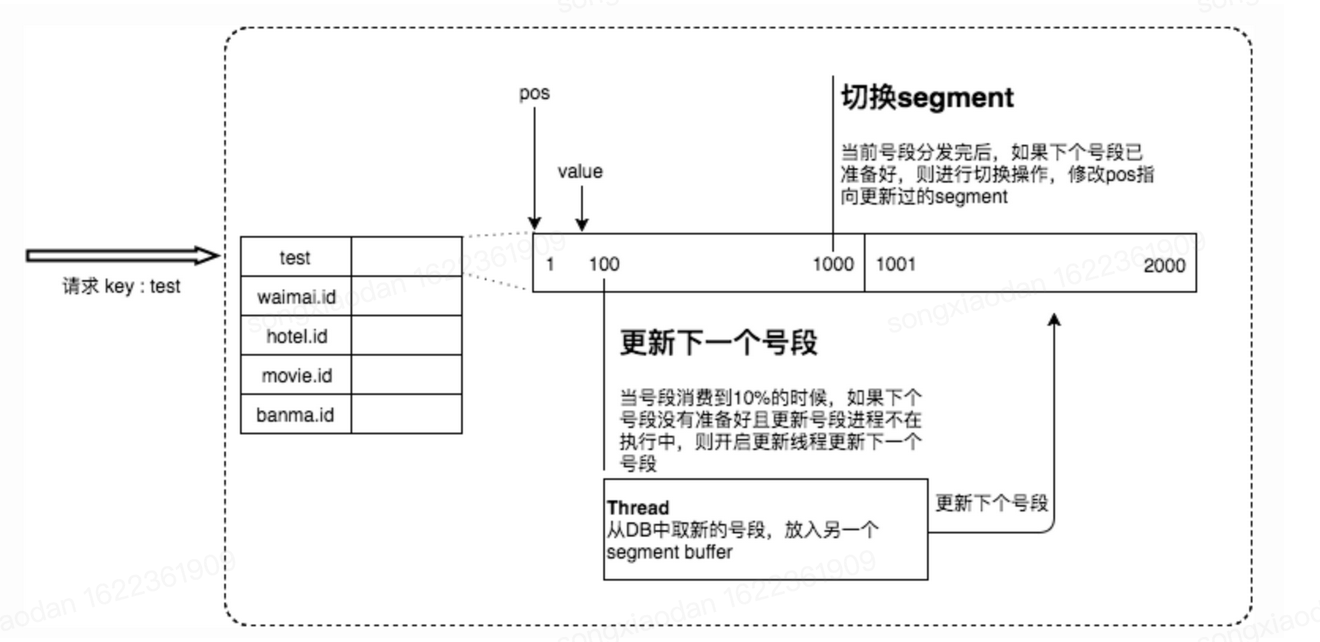
【号段模式改进】
基于数据库号段模式,但取号段的时机不在号段消耗完的时候进行,而是当号段消费到某个点时就异步的把下一个号段加载到内存中,好处是不阻塞临界点的ID下发。
【雪花算法改进——解决时钟回退方案】
- 启动时: a. 弱依赖ZooKeeper,由Zookeepp的持久化顺序节点来存储wokerId。若写过,则用自身系统时间与leaf_forever/${self}节点记录时间做比较,若小于leaf_forever/${self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警。 b. 若未写过,证明是新服务节点,直接创建持久节点leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。 c. 若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self} 维持租约。 d. 否则认为本机系统时间发生大步长偏移,启动失败并报警。 e. 每隔一段时间(3s)上报自身系统时间写入leaf_forever/${self}。
- 运行时:
a. 建议可以直接关闭NTP同步;【Network Time Protocol(NTP)】
b. 做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警;
【主要代码】 号段模式:
//LeafController.class
@RequestMapping(value = "/api/segment/get/{key}")
public String getSegmentId(@PathVariable("key") String key) {
return get(key, segmentService.getId(key));
}
//SegmentIDGenImpl.class
@Override
public Result get(final String key) {
// 将初始值和步长初始化
if (!initOK) {
return new Result(EXCEPTION_ID_IDCACHE_INIT_FALSE, Status.EXCEPTION);
}
// key为业务标识
if (cache.containsKey(key)) {
SegmentBuffer buffer = cache.get(key);
// 如果当前还没有初始化号段
if (!buffer.isInitOk()) {
synchronized (buffer) {
if (!buffer.isInitOk()) {
try {
updateSegmentFromDb(key, buffer.getCurrent());
logger.info("Init buffer. Update leafkey {} {} from db", key, buffer.getCurrent());
buffer.setInitOk(true);
} catch (Exception e) {
logger.warn("Init buffer {} exception", buffer.getCurrent(), e);
}
}
}
}
// 从缓存中取值
return getIdFromSegmentBuffer(cache.get(key));
}
return new Result(EXCEPTION_ID_KEY_NOT_EXISTS, Status.EXCEPTION);
}
private ExecutorService service = new ThreadPoolExecutor(5, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), new UpdateThreadFactory());
public Result getIdFromSegmentBuffer(final SegmentBuffer buffer) {
while (true) {
buffer.rLock().lock();
try {
final Segment segment = buffer.getCurrent();
// 当号段消费到某个点时就异步的把下一个号段加载到内存中
if (!buffer.isNextReady() && (segment.getIdle() < 0.9 * segment.getStep()) && buffer.getThreadRunning().compareAndSet(false, true)) {
service.execute(new Runnable() {
@Override
public void run() {
Segment next = buffer.getSegments()[buffer.nextPos()];
boolean updateOk = false;
try {
updateSegmentFromDb(buffer.getKey(), next);
updateOk = true;
logger.info("update segment {} from db {}", buffer.getKey(), next);
} catch (Exception e) {
logger.warn(buffer.getKey() + " updateSegmentFromDb exception", e);
} finally {
if (updateOk) {
buffer.wLock().lock();
buffer.setNextReady(true);
buffer.getThreadRunning().set(false);
buffer.wLock().unlock();
} else {
buffer.getThreadRunning().set(false);
}
}
}
});
}
long value = segment.getValue().getAndIncrement();
if (value < segment.getMax()) {
return new Result(value, Status.SUCCESS);
}
} finally {
buffer.rLock().unlock();
}
waitAndSleep(buffer);
buffer.wLock().lock();
try {
final Segment segment = buffer.getCurrent();
long value = segment.getValue().getAndIncrement();
if (value < segment.getMax()) {
return new Result(value, Status.SUCCESS);
}
if (buffer.isNextReady()) {
buffer.switchPos();
buffer.setNextReady(false);
} else {
logger.error("Both two segments in {} are not ready!", buffer);
return new Result(EXCEPTION_ID_TWO_SEGMENTS_ARE_NULL, Status.EXCEPTION);
}
} finally {
buffer.wLock().unlock();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
雪花算法:
//LeafController.class
@RequestMapping(value = "/api/snowflake/get/{key}")
public String getSnowflakeId(@PathVariable("key") String key) {
return get(key, snowflakeService.getId(key));
}
//SnowflakeIDGenImpl.class
public synchronized Result get(String key) {
long timestamp = timeGen();
// 当前时间小于上次用的时间戳
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
try {
// 时间偏差大小如果小于5ms,则等待两倍时间
wait(offset << 1);
// 重新获取时间戳
timestamp = timeGen();
if (timestamp < lastTimestamp) {
return new Result(-1, Status.EXCEPTION);
}
} catch (InterruptedException e) {
LOGGER.error("wait interrupted");
return new Result(-2, Status.EXCEPTION);
}
} else {
return new Result(-3, Status.EXCEPTION);
}
}
// 当前时间 = 上次的时间戳
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
//seq 为0的时候表示是下一毫秒时间开始对seq做随机
sequence = RANDOM.nextInt(100);
timestamp = tilNextMillis(lastTimestamp);
}
} else {
//如果是新的ms开始
sequence = RANDOM.nextInt(100);
}
lastTimestamp = timestamp;
long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence;
return new Result(id, Status.SUCCESS);
}
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
protected long timeGen() {
return System.currentTimeMillis();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 7.uid-generator(百度)
【文档】 https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md 【组成】 ● sign(1bit) ● 固定1bit符号标识,即生成的UID为正数。 ● delta seconds (28 bits) ● 当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年 ● worker id (22 bits) ● 机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。 ● sequence (13 bits) ● 每秒下的并发序列,13 bits可支持每秒8192个并发。 以上参数均可通过Spring进行自定义
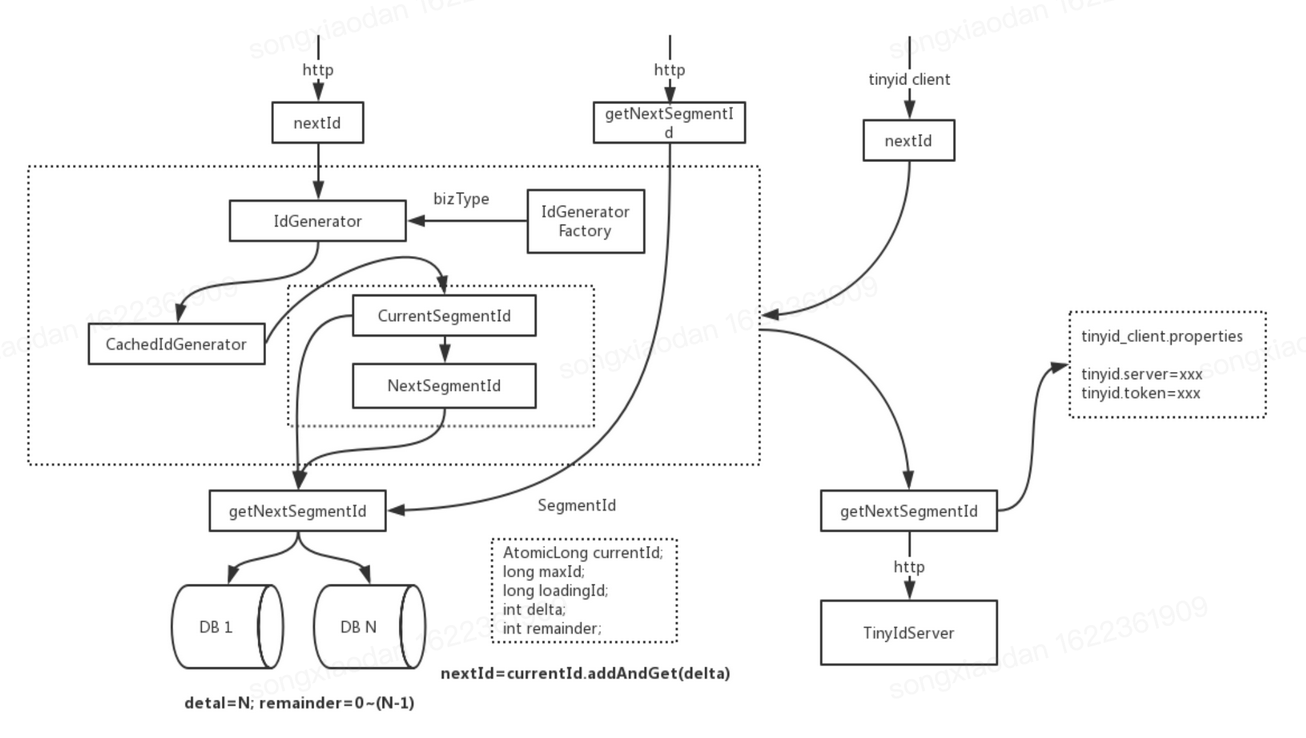
# 8.Tinyid(滴滴)
Tinyid扩展了leaf-segment算法,支持了多db(master),同时提供了java-client(sdk)使id生成本地化。 【优点】
- 提供http和java client方式接入
- 支持批量获取id
- 支持生成1,3,5,7,9...序列的id(其实就是for循环获取)
- 支持多个db的配置,无单点
# 结语
对比了几种分布式id的方案,个人认为美团的实现方案是比较完善的,它对业界比较流行的两种方案(号段模式和雪花算法)均有改进,且百度、滴滴的方案均基于它来实现。
如果想要更简便的方式,UUID、UUID转Long、Redis自增方案是不错的选择,可以按各自的优缺点去选择方案。因为没有最优,只有最合适业务的方案。